
The Problem of Junk Articles
Newsgroups are a popuplar target for spammers, who can easily and cheaply send out lots of junk messages to newsgroups, with the hope that enough people will see them that a few actually read them, and enter into business with the spammer. There is also a set of people who use spam on newsgroups to push their particular political or religious agenda, resulting in more junk messages that you don't want to see.
How much junk you see on newsgroups depends on a couple of factors, namely which newsgroups you read (some have more junk than others), and whether your news provider does their own junk filtering. Some do, and make a pretty good job of it, but there are always articles that get through.
You could spend a lot of time setting up a collection of filters to catch as many of these junk messages as you can. For example, you might set up filters to catch posts with "money" or "viagra" in the subject line. However, you'd be chasing a constantly moving target, as different kinds of junk messages show up.
To help address the issue of junk, MT-NewsWatcher now includes a special "Junk Message" filter, which, under the covers uses probabilities to make a guess about which articles are junk, and learns as you train it. It works in a similar way to the "Bayesian filters" that many mail clients now have.
Not only does this single filter take care of identifying all kinds of junk messages, it also learns as you train it, which means that it learns to recognize messages that are junk to you (but may be non-junk to someone else).
How Junk Filtering Works
To make the junk message filter good at separating the junk from the non-junk, you have to train it. This is done by telling the program that specific messages are junk or not junk. This is known as training the junk filter. When you train the filter with "good" and "bad" articles, it looks at the words in the headers of those articles, and adds them to lists of "good" and "bad" words. This body of information is called the "Training data", or sometimes the "corpus".
It's important to realize that this training is not automatic. You have to manually specify which articles are good and bad in order to train the filter. This keeps the filter honed and accurate. To alleviate having to training a lot when you first start using the junk filtering, MT-NewsWatcher has a default set of training data.
When it has this set of "good" words and "bad" words, the junk filter looks at the headers of incoming articles, and matches up the words in them to the "good" and "bad words. Based on the relative frequencies of those words, the filter classifies the message as junk or not junk. This is where the Bayesian probability comes in.
As an example, suppose that you mark several articles with "viagra" in the subject line as junk. The filter then notices that "viagra" often occurs in junk messages, and is thus more likely to classify incoming articles mentioning "viagra" as junk.
Note: Remember that the filtering is based on probabilities. You can't expect it to be 100% accurate. In fact, the filter is somewhat biased against marking messages as junk, because it would be bad to mark too many good messages as junk (you'd miss reading them). Similarly, you can't expect that marking one "viagra" message as junk will instantly cause all other "viagra" messages to be caught. Because of the relative probabilities of "viagra" and other words in the articles, you may have to mark several "viagra" messages as junk before the weight of the "viagra" term is sufficiently large.
Because the classification is based on probabilities, it's hard to tell why any specific message is classified as junk or not junk. The filter considers the whole set of words in the headers, and doesn't classify something as junk just because it has one specific word in the headers.
A limitation of the junk filtering in MT-NewsWatcher is that the program has only messages headers to classify, not the full article text, to classify. The program goes to some lengths to extract as much information as possible from the headers, but it may not do quite as well as a filter that has the full article text available (such as in a mail client).
Despite these apparent shortcomings, as long as you train the filter when necessary, you'll find that over time, the junk filter becomes uncannily accurate. Persevere!
Using a Junk Filter
Creating a Junk Filter
When you run MT-NewsWatcher for the first time (or upgraded to the first version with junk filtering), a junk filter is created for you. It will show up as the last filter in the global "*" category:
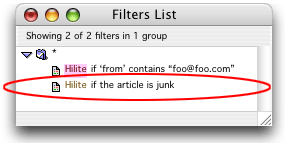
This filter behaves just like other filters. You can move it to a different group category if you want it to apply to only a subset of groups. You can specify that other filters shouldn't override it and you can change the behavior, assigned score and highlight colors.
The filter is created as a "Highlight" filter with a low score initially, so that you notice whether articles are getting marked as junk and can train it. Once you've trained it sufficiently well, you could change it to a "Kill" filter, so that junk messages would be removed automatically.
If this filter is missing, you can easily make a new one. Just create a new filter, and choose "Message is Junk" from the popup menu.
Note: All junk filters use the same set of training data. Normally you'd only want one junk filter.
When you open a newgroup which has some junk messages in, they should get highlighted in brown, and drawn in italics (by default), like the second message here:
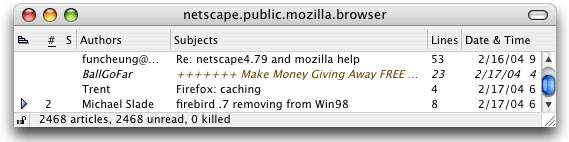
The italics show that this message has been classified as junk. When you mark as message as junk, it will also show in italics.
Training the Junk Filter
As described above, training is important in getting a a good junk filter. When you see a junk messages that has not already been marked as junk, select it and choose from the menu. Similarly, if you see a good messages that has been marked as junk, select it and choose from the menu.
Training is an on-going process. How often you need to train will depend on how many articles have been used to train the filter so far, and whether the incoming articles are qualitatively similar to those used to train the filter. If a new kind of spam shows up, you may have to mark a few of those spam articles as junk to retrain the filter.
Resetting the Junk Filter
Sometimes, you might find that you want to reset the junk filter, and start training again from scratch. In fact, there are two states you can go back to: the default training data that is shipped with MT-NewsWatcher, or a totally clean state with no training data.
To reset the training data, go to the "Filtering & Junk" panel of the Preferences dialog. There, in the lower right, you'll see a Reset... button. Click this button, and you'll be asked to confirm whether to reset the training data to the default set. Click Reset to go ahead.
To totally clear the training data, hold down the Option key while clicking the Reset... button. Again, you'll be prompted to confirm whether to do this. Click Reset to confirm.
Warning: If you totally reset the training data (by Option-clicking the Reset button), then the junk message filter has no data to work with. In this situation, it will mark every message as junk. You will have to train it to identify non-junk messages by selecting a group (say 50) good messages, and choosing on the menu. It will then probably mark some junk as good, so you'll have to select any such articles, and . Lather, rinse, repeat, until you have a good filter again.
Where Information is Stored on Disk
The junk filter training data is stored in a file called (not surprisingly) "Junk Filter Training Data" in the "MT-NewsWatcher Prefs" folder alongside the other preferences files. This is just a text file, so you can open it with your favorite text editor and browse around. However, you are not advised to try to "improve" the filter by twiddling the numbers. Only the MT-NewsWatcher really knows what those numbers mean.
Table of Contents
- Preface
- Table of Contents
- Introduction
- Features
- Advanced features
- The Interface
- Appendices